Coding Agents: AI Driven Dev Conference
I am trying to make better use of all the meetups, conferences, startup events, and overall the energy and excitement in the Bay Area - in particular around agentic AI and coding agents. So yesterday, I attended the Coding Agents: AI Driven Dev Conference, hosted by the San Francisco MLOps Community at the Computer History Museum in Mountain View, California. This full-day event covered a lot of ground around the entire development and deployment lifecycle of agentic systems (both single agent and multi-agent) and featured a startup-heavy lineup of speakers, demos, booths, and keynotes. All slides and the full livestream recording are linked in the conference materials section below.
Overall Reflections
This was one of my first conferences in the Bay Area (apart from OpenAI’s dev day and GTC last year) but it definitely won’t be my last. The energy and excitement around agentic AI and coding agents was palpable and attendees were eager to talk about their experiments, workflows, setups, and learnings. But besides that, it was really valuable to see how the community is thinking about agentic AI and which directions startups are pursuing. I’ll go into these topics in more detail below in the individual talk sections and focus on overall conference impressions here.
- There were about 400 people in attendance, 19 startup booths, 8 keynotes, 5 lightning talks, and 3 workshops.
- Mountain View’s Computer History Museum was a really fitting venue for this event - the future of software engineering and knowledge work against the backdrop of the history of computing (some speakers explicitly referenced the history of computing in their talks).
- Overall, the event had a great energy - especially from the organizer Demetrios.
- I’ve never heard the word “orchestration” used so many times in a single day before.
- I can’t shake the impression that we are living through a bimodal adoption distribution. On the one hand you see startups building hardcore multi-agent systems, traceability and observability systems, etc. On the other hand, you see participants at these conferences just barely using single-agent systems, coding assistants, or MCPs in their daily work. Even at NVIDIA, adoption is still quite uneven. Kilo’s keynote captures this quite well — “Developers don’t jump to agents. They climb.” The path to multi-agent orchestration is a long one and I see my job as early adopter / evangelist to make that learning curve less steep and simplify their onboarding (at least that is what I try to do at NVIDIA and with my blog posts).







Keynote: Sid Bidasaria - Anthropic
Fireside Chat with the Co-creator of Claude Code. The opening keynote was a fireside chat with Sid Bidasaria, co-creator of Claude Code. Overall, great intro talk to start off the day.

Browser verification via Chrome. Claude Code can verify its work using a Chrome browser via the /chrome command (see this post for more details). The tricky part is remote execution — in container environments where they use a port-forwarding setup.
Give the agent access to everything you can see. Give Claude Code access to your log server (Datadog, etc.), your monitoring dashboards, your error tracking — all the things you can see as an engineer. The more context the agent has, the better it performs.
Skills and MCP servers are the two primitives that matter. The Anthropic team still uses MCP servers and memory systems. Skills are “context blobs” — a more generalizable version of claude.md / agent.md files. Sid’s framing: all the models need is access to the right tools (MCP servers) plus instructions on how to use them (skills). Complicated harnesses all boil down to these two things.
Running agents in parallel is still hard. Orchestrating agents manually is tricky — one agent finishes faster than you can spin up the next one. Sid described his personal system:
- 5 pre-defined work trees on his laptop
- Opens a new iTerm window with a new Claude Code session per work tree
- As the agent works, it updates the iTerm window title (and work tree name)
- Remote sessions controlled from his phone add another layer of complexity
- He doesn’t one-shot everything — he increases agency incrementally, and each result spurs more ideas
Code review with Claude Code is a superpower. The team relies heavily on Claude Code to review PRs on GitHub via a custom harness. It reviews each PR in three different ways with calibrated confidence levels to keep noise down. Claude Code ends up finding a lot of bugs — reducing the human burden of scrutinizing every line for edge cases.
Meta is submitting prompts alongside PRs. Interesting signal that the prompt/plan that generated the code is becoming a first-class artifact.
Plans are the highest-leverage artifact. The most useful thing for Sid is the plan you come up with before Claude Code builds code. He advocates for a plans/ or docs/ folder in the codebase where feature plans live. He uses plan mode extensively — having Claude Code interview him before building. These high-density plan files have a direct correlation to build success and remain useful for both humans and Claude Code down the line.
Precision over recall in code reviews. The key optimization was reducing noisy 5-10 comment reviews down to 2 high-priority comments. Focus on precision. The bar for approving PRs has gone down because the person who wrote the code (or directed the agent) is responsible regardless. Quick remediation beats preventing all bugs — you will have bugs either way.
My Take
- It’s always interesting to hear about different developer setups - especially from the creators of a tool. I was mostly interested in the level of parallelism Sid uses, which seems to be the same order of magnitude as my own setup. While that is somewhat comforting to hear, I am still looking for ways to scale that up without making it completely exhausting to keep agents busy.
- The setup Sid uses is not all that different from what I use (Sid mentioned that he uses a handful of agents and not full Gastown-scale multi-agent orchestration). Even Anthropic engineers (and Claude Code creators) are just people ;).
- Sid touches upon spec-driven development in his statement about using design docs and implementation plans. This is in line with a number of other talks at the conference and also with Claude Code’s (or Cursor’s) switch to plan mode before starting to implement anything. These design docs take on more of a primary artifact status in software engineering and serve to document design intent and decisions (to explain the thinking behind the code).
- When it comes to code review, I keep hearing that companies like OpenAI and Anthropic use them to great effect. I have seen iterations of this at NVIDIA as well, but the signal-to-noise ratio was always too low to be useful. Most often, the review agent would only point out trivial or low-level issues but not more abstract issues about whether a certain PR fits into the overall architecture, whether it clashes with previous design decisions, whether it’s scalable, efficient, etc. In my opinion, a good review agent needs access to a lot more context (the artifacts beside the code that explain design intent/decisions, the overall vision for the project, etc.) to be able to provide meaningful feedback. I think this will improve massively once we include related artifacts in the code repositories (similar to what Thomas Dohmke (CEO of Github) is pursuing with his new startup Entire). This is also a topic that the workshop by Drew Breunig covered in more detail (see my section on Drew Breunig’s workshop below).
Keynote: Scott Breitenother - Kilo Code
Building at Scale with Coding Agents. Scott Breitenother shared how Kilo Code operates — 25 trillion tokens processed since launching in May, 1.5 million developers. What stood out about this talk was less about the product (or rather the impressive slate of products they offer) and more about their radical organizational philosophy.
Avoid collaboration at all costs. This was a deliberately provocative framing. Most collaboration is a safety blanket to feel comfortable — not a value-add. Scott recommended only collaborating when truly necessary. Instead, they practice end-to-end ownership: one engineer owns the entire feature, not a team.
In the age of AI, coding is the easy part. The challenge has shifted to processes — deployment, monitoring, and the glue around the code. Some of the biggest gains are in deployment and monitoring workflows, not code generation. Scott stated that “The proof is in production.”, i.e. showing that the system works in production is the ultimate litmus test of whether a feature works as intended and that a code review is insufficient to guarantee that.
Developers at Kilo manage teams of 3-5 agents. At any given time, devs use 2-4 agents in parallel, each with different roles: orchestrator, architect, coder, debugger, asker. Customizing these agent personas to your needs is critical.
User trust is everything. If latency spikes, suggestions are wrong or slow, file paths are incorrect, or review load is too high — usage drops immediately. To earn trust and move from tab-complete to chat to agent to full orchestration, you have to give the AI more and more context (“open up the books”).
Pick the right model for the job. SOTA models for architecting and reviewing. Something cheaper (Minimax, GLM) for building, debugging, and asking questions.
40 hours of orchestrating is harder than 40 hours of coding. Thinking, architecting, and directing agents full-time is significantly more mentally taxing than writing code. Scott’s observation was that companies’ expectations have to be updated to reflect this (i.e. companies should not be expecting 40 hours of multi-agent orchestration from their employees).
One-person teams. Kilo has one-person teams. If that person is on vacation, the feature doesn’t move.
My Take
- The statement about earning user trust really resonated with me. I’ve seen this firsthand at NVIDIA in the early stages of coding assistants (back then we used TabNine’s tab-complete feature). There are only so many low quality tab completions a user will tolerate before disabling the tool altogether. A similar story unfolded with code review agents that introduced only low quality noise instead of meaningful feedback.
- Somewhat related to earning user trust is the ease of use. So far what I’ve found is that coding assistants, (AI-enabled) tools, or agents get adopted much faster when they are trivial to set up and use. For example, instead of setting up a dozen MCP servers at NVIDIA, we’ve resorted to a unified CLI that absorbs the functionality of all those MCP servers and can be installed with a single
make installcommand. Even authentication can be simplified via the Makefile and the user can be guided through the process of fetching all required credentials. This much improved user experience is already leading to much faster adoption across the org. - The significant mental load of orchestrating multiple agents in parallel is not to be underestimated. The cognitive load of constant context switching, monitoring agent outputs, authorizing tool use requests, etc. is a very different mode of operating as a software engineer and is in dire need of better solutions. I could see a model where a developer uses committees or councils of agents to help them with their work to offload some of the cognitive load. Gastown was exploring that idea and I’ve also seen code review done by a council of different models but this is definitely an area that is under-explored.
- Scott’s observation that one should pick the best model for the job is something that I’ve had to grapple with in my personal projects (where I wanted to keep the inference cost low, e.g. in my Second Brain project). At NVIDIA, I have the luxury of being able to use the best model (currently I think that’s Claude 4.6 Opus).











Keynote: Jesse Wang - Braintrust
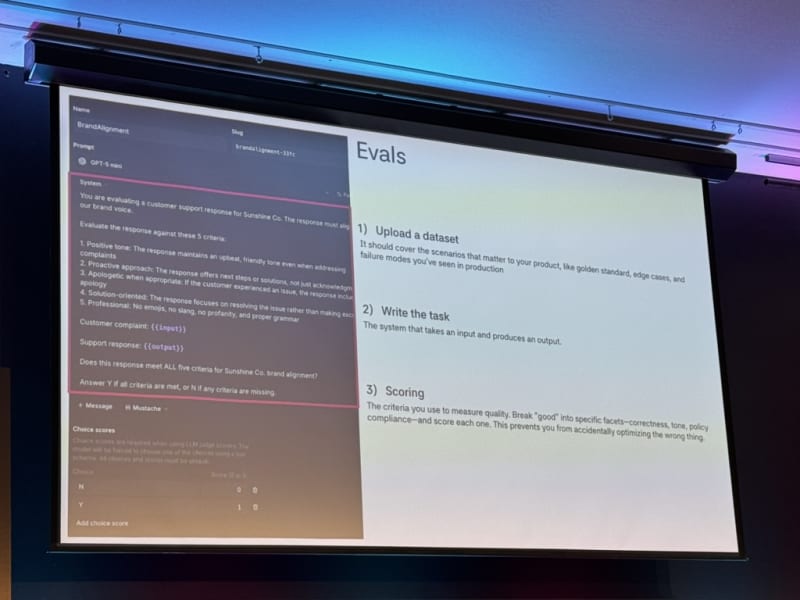
Evaluation for LLM Use-Cases. Jesse Wang presented Braintrust’s approach to evaluation for LLM use-cases. Braintrust is an evaluation platform (reminiscent of OpenAI’s eval system) with a feature called “Loop” for iterative evaluation.
Evals are living, breathing machines. They involve many components and evolve over time — they’re not a one-time setup.
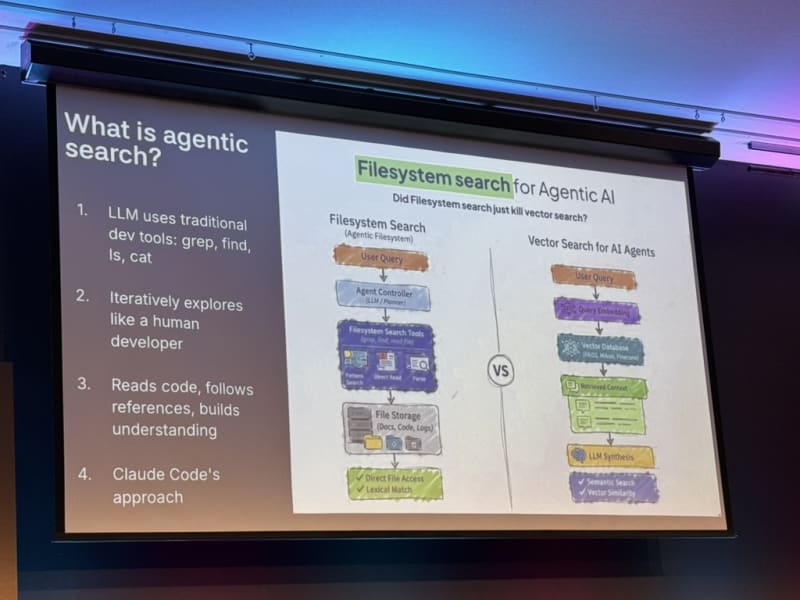
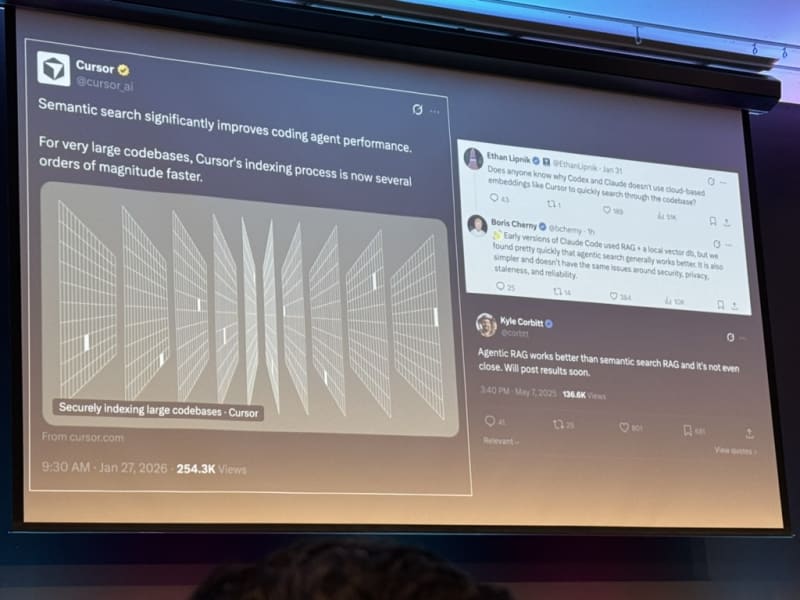
Agentic search beats vector search. This was one of the most striking claims of the day. Traditional vector DB approaches require chunking text and rely on embedding similarity. Agentic search instead uses filesystem-based search — the way most LLMs and Claude Code actually work: iterative search, open file, grep, open another file, use another tool, and so on. This is much more powerful than pure vector search. Boris Cherny (the creator of Claude Code) also mentioned the power of agentic search in a recent interview on the Pragmatic Engineer newsletter.
Claude Code’s “agentic search” is really just glob and grep — and it outperformed RAG. The team tried several approaches to make agentic search better: local vector databases, recursive model-based indexing, and other fancy approaches. All had downsides (stale indexes, permission complexity). Plain glob and grep, driven by the model, beat everything. This approach was inspired by how Boris observed engineers at Instagram searched code when the click-to-definition functionality in Meta’s in-house coding editor was broken.
Tracing needs to cover the full agent tree. Good traces should include not just the main agent but all spawned sub-agents, their outputs, and every LLM call in the hierarchy - and combine all that data into a single trace.
My Take
- The most eye-opening part of this talk was the power of agentic search (over RAG-based approaches). Jesse advised to take these results with a grain of salt but given the widespread use of Markdown / file-based memory architectures (not just in Claude Code but also in OpenClaw and derivative personal assistants) it makes me revisit my assumptions about how to build a memory system for an agent. It also makes me think that any memory system I build for an agent needs quantitative evaluation to measure the retrieval performance (and to be honest, memory eval has not been at the forefront of my mind when building agentic systems).
- To hedge my bets, I’d probably build a hybrid approach combining vector and agentic search since both approaches have unique strengths and weaknesses (e.g. regarding retrieval performance, speed, cost, token usage, etc.).



Keynote: Niels Bantilan - Union
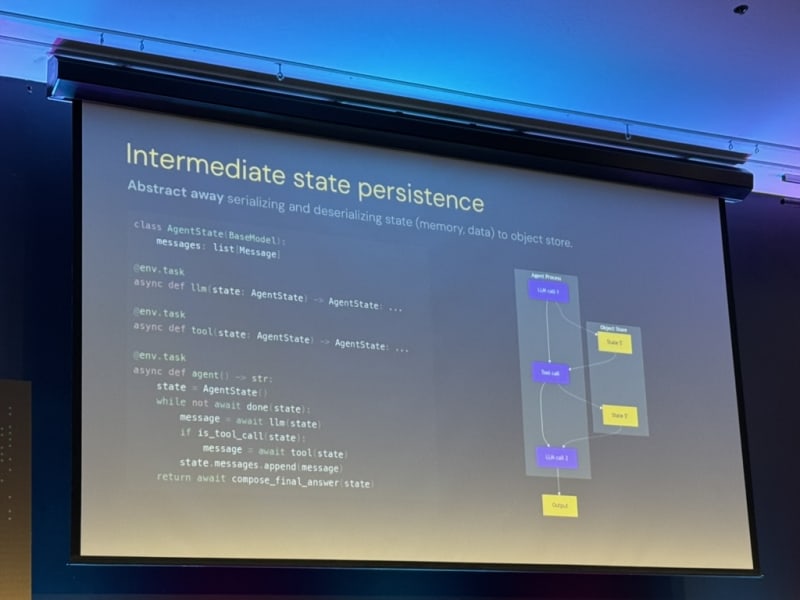
The Orchestration Stack for Observable, Debuggable, and Durable Agents. Niels Bantilan presented Union’s product Flyte and their approach to productionizing agentic systems through orchestration.
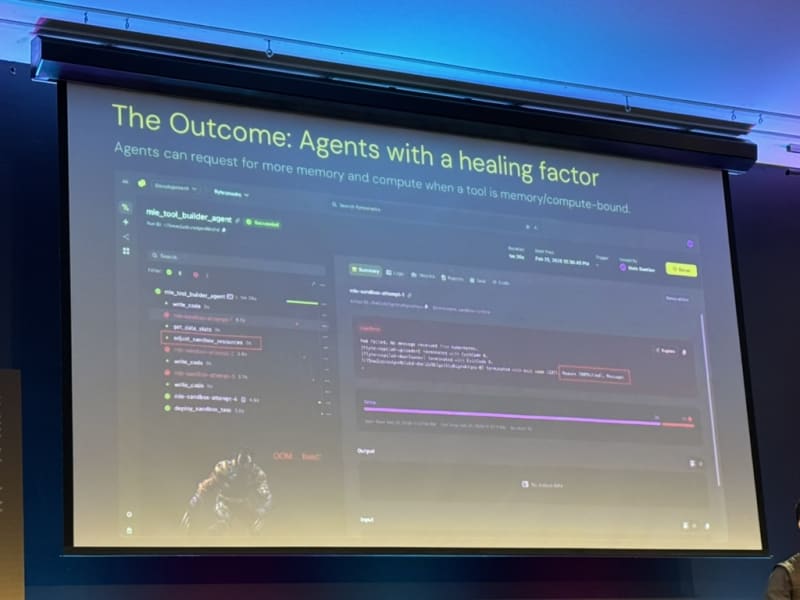
Agents need to provision their own compute. For heavier tasks, the agent should be able to spin up its own infrastructure rather than being constrained to a single environment (e.g. spin up a container with higher memory and CPU resources).
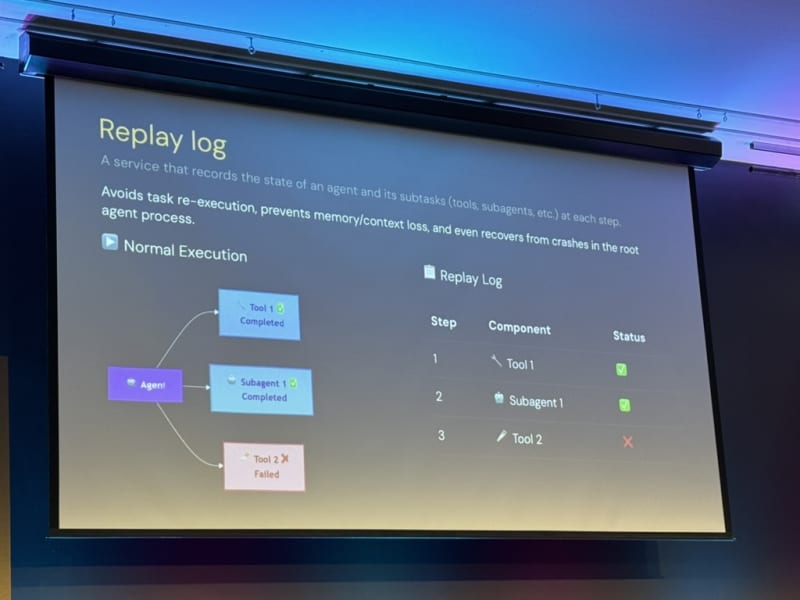
Self-healing agents are the goal. Agents can recover from infra failures if we give them the right context. Niels outlined five design principles:
- Use plain Python (or common languages like TS/JS) — avoid esoteric DSLs (Domain-Specific Languages)
- Durability and observability hooks — bake in logging and state recovery
- Make failures cheap — fast recovery over prevention
- Infrastructure as context — let agents see and fix infra issues
- Agent self-healing utilities — so the agent can fix its inner loop
Human-in-the-loop remains the final recourse and recovery method.
Security alternatives to OpenClaw. He mentioned Zero Claw and NanoClaw as more secure alternatives to OpenClaw for running agent-provisioned infrastructure.
My Take
- This keynote was more technical than the previous ones in the sense that Niels showed a number of code examples that made me excited about trying out their Flyte framework. The decorator-based approach for setting up environments, permissions/authentication, and logging seems to make it really easy to build and deploy agentic systems with Flyte.
- The idea of “self-healing agents” and giving agents more context to be able to fix infra-issues reminded me of an article I recently read about The Unreasonable Effectiveness of Closing the Loop. The “outer loop” is about making the feedback loop larger and larger and folding in more and more systems into the context of the agent (in this case infra systems, build systems, training clusters, etc.). You basically give the agent more context and more tools to fix issues and make it more self-sufficient. Definitely something I’ll be exploring at NVIDIA by enabling my agents to query our Jenkins build system.














Workshop: Mihail Eric - Stanford
5 Prompts to Ship Production Code 2x Faster. Mihail Eric (themodernsoftware.dev) teaches CS146S: The Modern Software Developer at Stanford (Fall 2025). His workshop introduced a prompting framework called RePPIT for systematically using AI in production workflows.
RePPIT framework:
- Research — Understand unfamiliar codebases
- Propose — Propose several solutions
- Plan — Plan out the most promising solution
- Implement — Execute the plan
- Test — Validate the implementation
The workshop felt like a polished Cursor introduction — but the underlying principle of having a repeatable, structured prompting workflow (rather than ad-hoc prompts) is the real takeaway.
My Take
- This talk felt like an introduction to software development using Cursor. It did a good job at formalizing the stages of the new software development paradigm that is anchored around automated implementation, which shifts the developer focus to the earlier research and design stages. Mihail emphasized the importance of iterating on the design proposal and implementation plan and only handing those plans off to the implementation agent once the design is well-defined and the implementation plan is clear.
- The RePPIT framework seems like a great way to formalize the software engineering process. Workshop materials: slides and full drive.
Workshop: Drew Breunig
A Software Library with No Code. Drew Breunig posed a provocative question: “If agents are good enough, do we need to share code?” He used his library whenwords (1.1k stars) as a case study. (examples, blog post, writeup, recording)
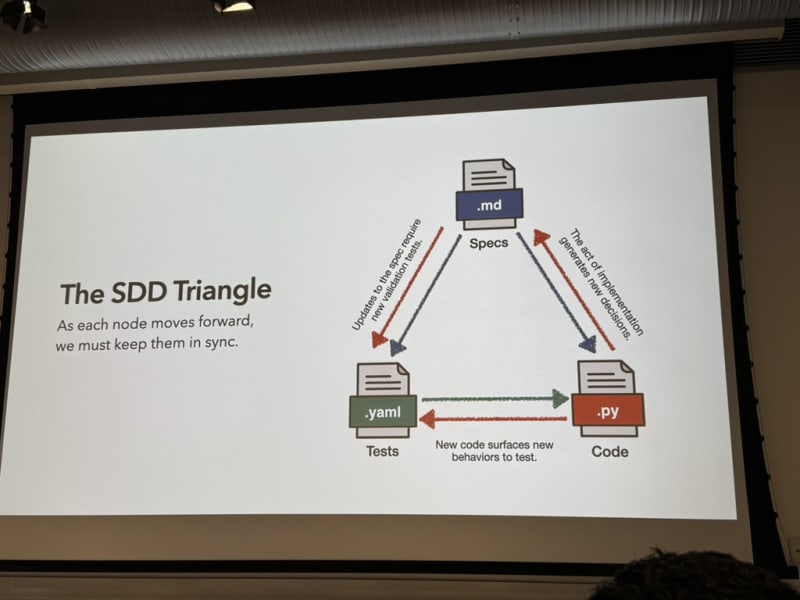
Spec-driven development — with caveats. Drew advocates for spec-driven development but cautions that specs and tests are sometimes not sufficient. No spec is perfect, and implementing the code helps us improve the spec. It’s not a one-way road — it’s a feedback loop.
The spec-test-code triangle. The typical assumption is Spec + Tests → Code (one-way). Drew argues it’s actually a triangle where each vertex influences the other two:
- Spec influences tests and code
- Implementing code surfaces spec gaps
- Tests reveal ambiguities in both
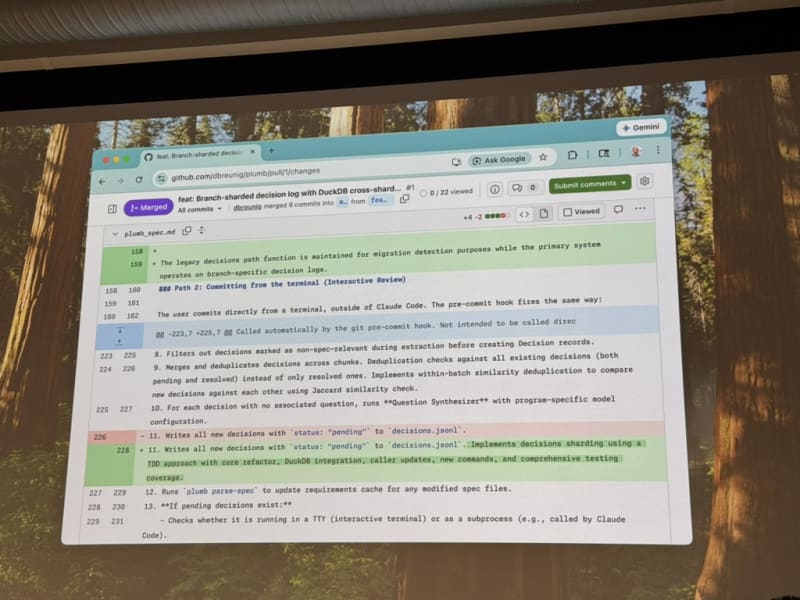
Project “plumb.” All context and decisions are tracked in GitHub alongside the code — not just the final implementation. You can reconstruct the reasoning and requirements from the repository history (see GitHub repo for plumb)
My Take
- This is exactly what Thomas Dohmke is pursuing with his new startup Entire - tracking all context and decisions that explain how and why a piece of code was written — and tracking these artifacts alongside the code in Git such that an agent has all required context to reason about the code.
- In my current setup, I commit design docs and implementation plans to the code repository but plumb tracks decision and design choices on a more granular level (almost on a turn-by-turn basis when conversing with the coding agent). I’ll definitely give plumb a try to see if it fits my workflow.















Keynote: Harrison Chase - LangChain
Agent Infrastructure and the Agent Builder Platform. Harrison Chase presented LangChain’s vision for agent infrastructure and their agent builder platform.
Agent harness design. LangChain’s agent harness is inspired by Claude Code and supports skills out of the box. Key design principles:
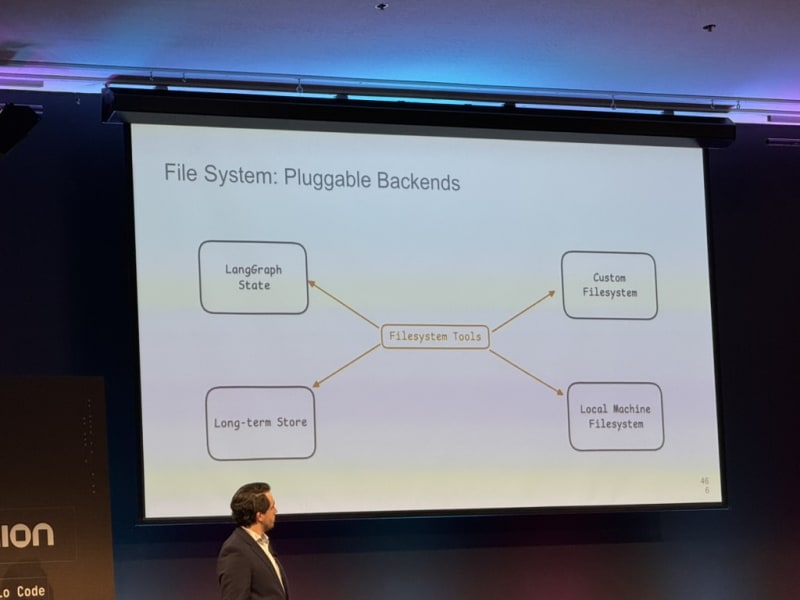
- Offload large tool results to a file that the LLM reads on demand (keeping context lean)
- Give the LLM more control over its own context
- Support for context compaction
Tool runtime = actions + control + auth. This clean separation makes it easier to reason about what an agent can do, how it decides, and what it’s allowed to access.
CLI is not the best interface for agents. Harrison thinks the future is closer to something like Claude Cowork — more collaborative and less terminal-driven. I think this point was made in the context of user experience (UX) rather than technical feasibility. CLIs are barely the best UI for engineers, definitely not for end-users.
Agent builder. 8,000+ tools, agent templates (e.g., email agent), and Arcade integration for pre-built tool sets. The Mac mini trick for blue bubble / iMessage access was a fun detail.
Channels and skills. LangChain’s concept of channels (communication primitives) and skills (reusable capabilities) as first-class building blocks for agent workflows.
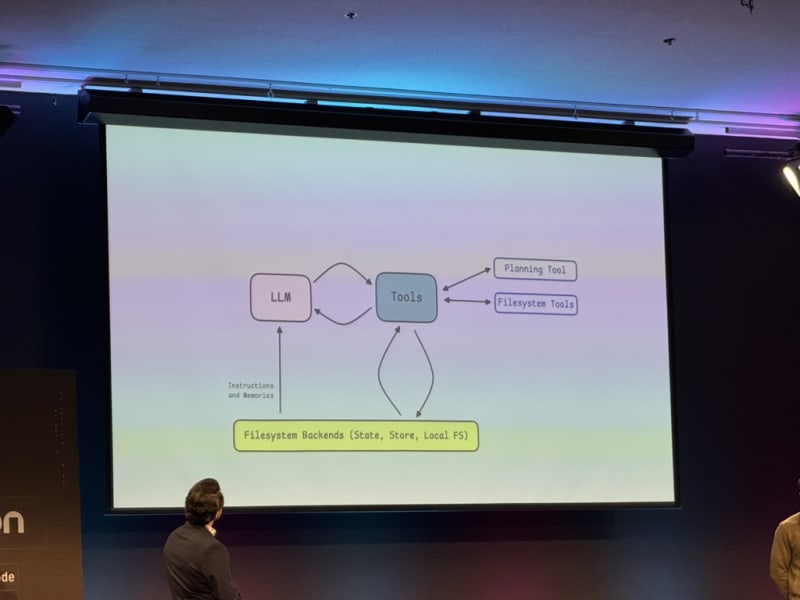
In short, Harrison laid out a three-layer stack: tools at the bottom (atomic capabilities split into actions, control, and auth), a harness in the middle (the agent runtime that adds skills, context management, compaction, and channels — heavily inspired by Claude Code), and an agent builder at the top (a platform with 8,000+ tools and composable templates that abstracts away the wiring). The key thesis: CLI isn’t the right interface for agents — the future is closer to collaborative, cowork-style interaction.
My Take
- This is an exciting framework to try out. It seems like LangChain’s ecosystem has greatly expanded since my last encounter with it - especially in the agentic space with the addition of agent harnesses and tools. This seems similar in capabilities to Flyte (presented by Niels Bantilan in an earlier talk) - not sure yet which one to try first.




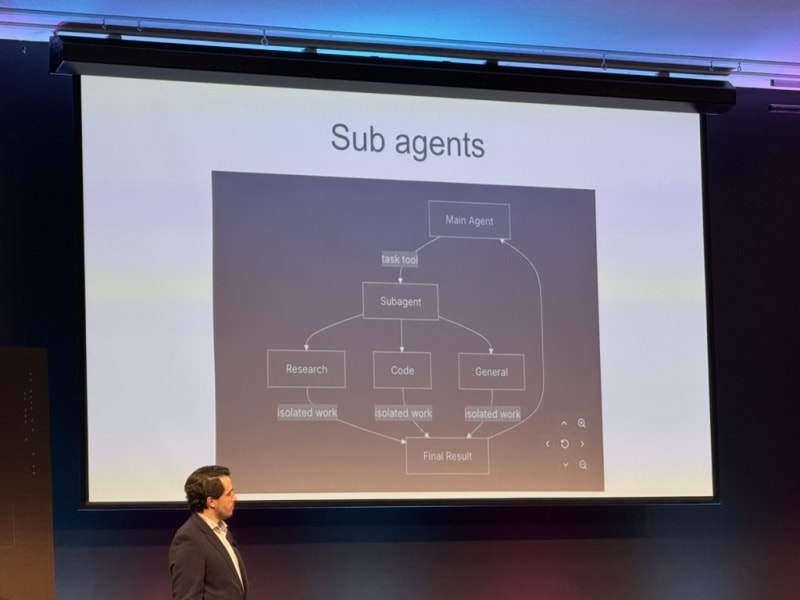

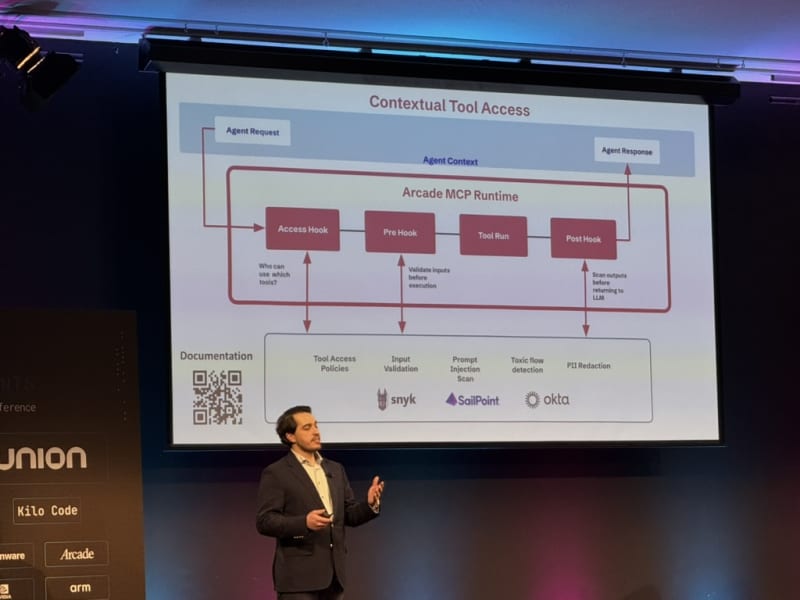

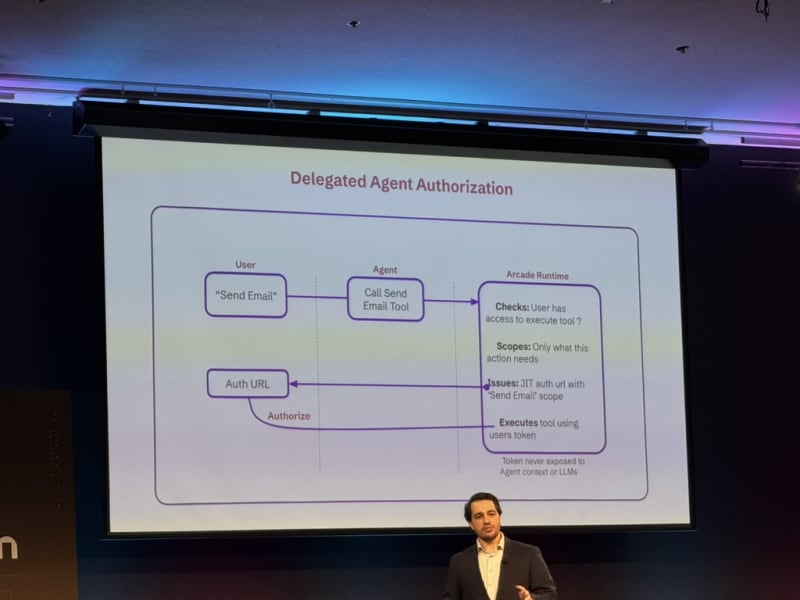

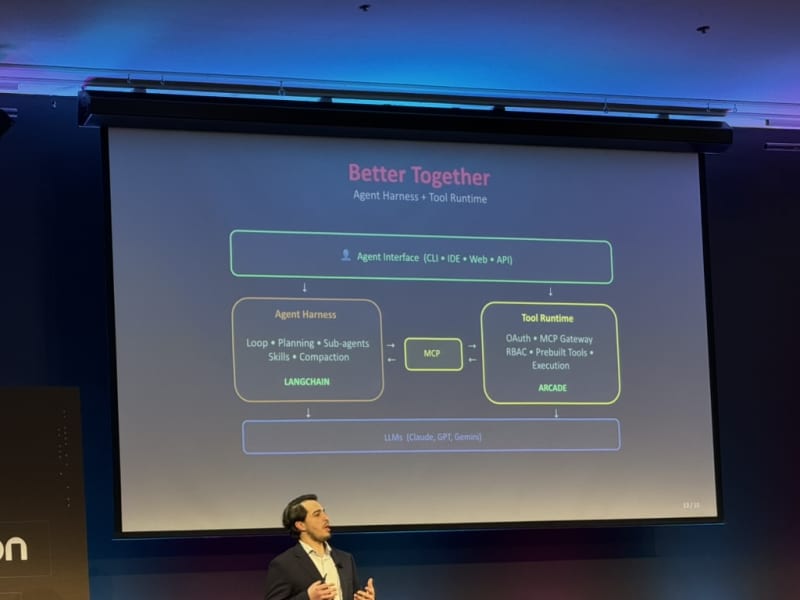

Conference Materials
New Contacts
Met some great people throughout the day:
- Benjamin Toney — USC
- Chris Collins — Intuit
- Jiquan Ngiam — MintMCP
- James Andrew Walsh — OpenClaw and Blender automation for luxury housing development
- Varuni Gang — TripAdvisor
- Anna Maria (AMB) Brunnhofer-Pedemonte — Impact AI, and her husband Stefanos
Workshop Materials
The organizer Demetrios shared workshop materials after the event:
- Optimizing Codebases for Agents — Shrivu Shankar: agent-first architecture patterns, “AI-Readiness” audit framework, and repo structure guidance. GitHub repo
- 5 Prompts to Ship Production Code 2x Faster — Mihail Eric: slides | full drive
- Software Libraries with No Code — Drew Breunig: writeup | recording
Overall, “Coding Agents” was an inspiring event that provided useful insights into the agentic AI space and how startups and developers in the space are thinking about the future of agentic systems. Clearly there is a trend towards a single developer managing larger and larger groups / swarms / hierarchies of agents.
Keep orchestrating!
Daniel